Raphael Voges, M. Sc.
Erstbetreuer: B. Wagner, Co-Betreuer: C. Brenner
With the advent of autonomous driving, the localization of mobile robots, especially without GNSS information, is becoming increasingly important. It must be ensured that the localization works robustly and timely warnings are provided if the pose estimates are too uncertain to assure a safe operation of the system. To meet these requirements, autonomous systems require reliable and trustworthy information about their environment. To improve the reliability and the integrity of information, and to be robust with respect to sensor failures, information from multiple sensors should be fused. However, this requires inter-sensor properties (e.g. the transformation between sensor coordinate systems) to be known. Naturally, neither the actual sensor measurements nor the inter-sensor properties can be determined without errors, and thus must be modeled accordingly during sensor fusion.
To localize autonomous vehicles without GNSS information in 3D, this work introduces a dead reckoning approach relying on information from a camera, a laser scanner and an IMU. Fig. 1 below shows an overview and highlights connections between the different components of this work that are explained in the following.
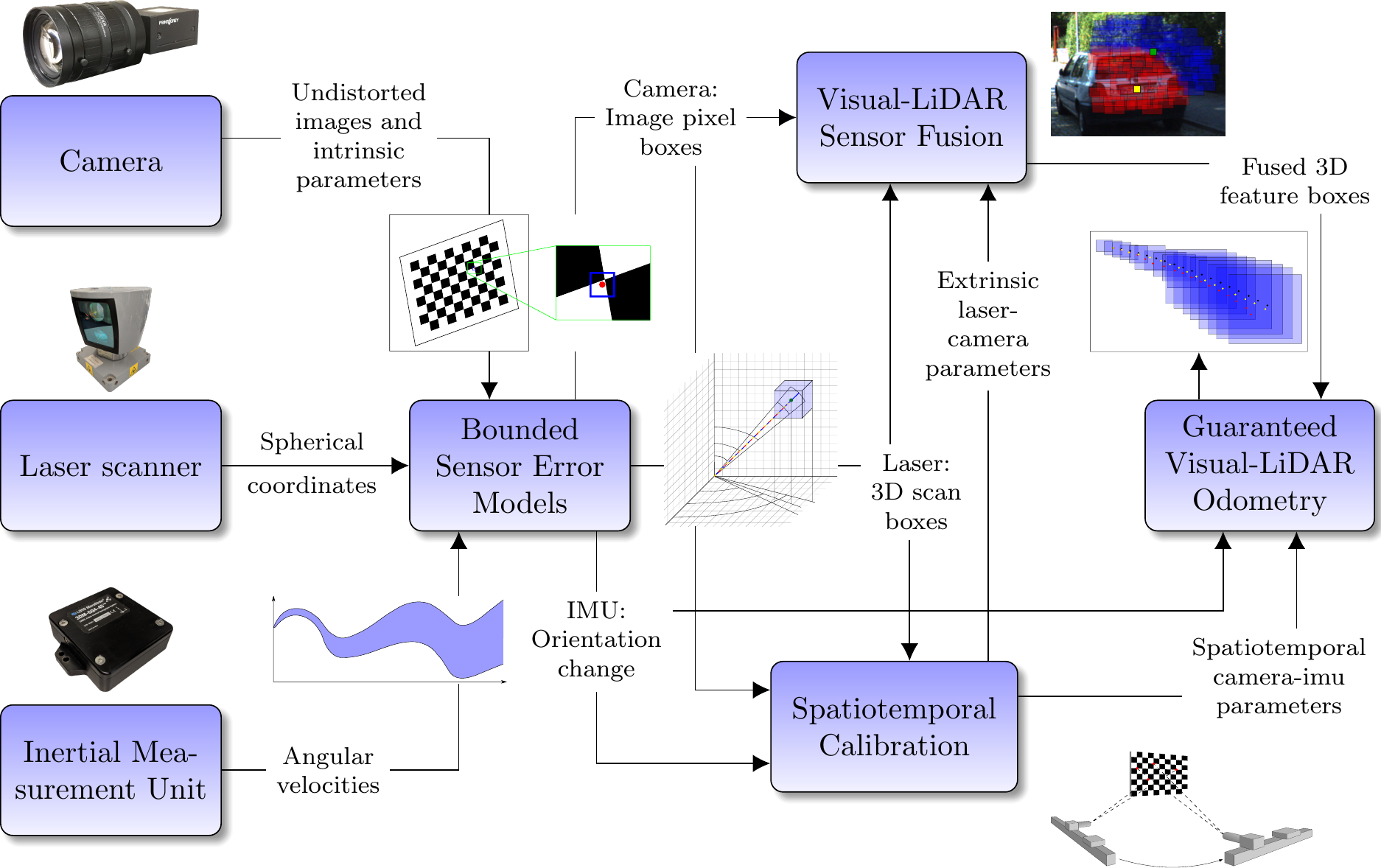
First, novel bounded error models for the individual sensors (camera, LiDAR and IMU) are introduced. Here, the errors are assumed to be unknown but bounded, which requires bounds (i.e. intervals) that are not exceeded by the actual sensor errors to be known. However, no further assumptions are required. In particular, the error distribution within the bounds does not need to be known, which is a frequently overlooked assumption of established approaches. Furthermore, interval-based error models are compatible with unknown systematic errors and can be used to guarantee results. Second, to determine the inter-sensor properties and the corresponding uncertainties, this thesis presents new approaches for the spatiotemporal calibration between camera, laser scanner and IMU that employ the proposed error models. Third, an innovative method that considers both sensor and inter-sensor errors for guaranteed visual-LiDAR sensor fusion is proposed. The fused information is subsequently used to perform interval-based dead reckoning (or visual-LiDAR odometry) of a mobile robot.
To evaluate the developed methods, both simulated and real data are analyzed. It becomes evident that all proposed approaches are guaranteed to enclose the true solution if the sensor error bounds are correct. Moreover, although interval-based approaches consider the ``worst case'', i.e. the maximum sensor errors, the results are reasonably accurate. In particular, it can be determined in which instances a state-of-the-art method computes a result that deviates significantly from the actual solution.
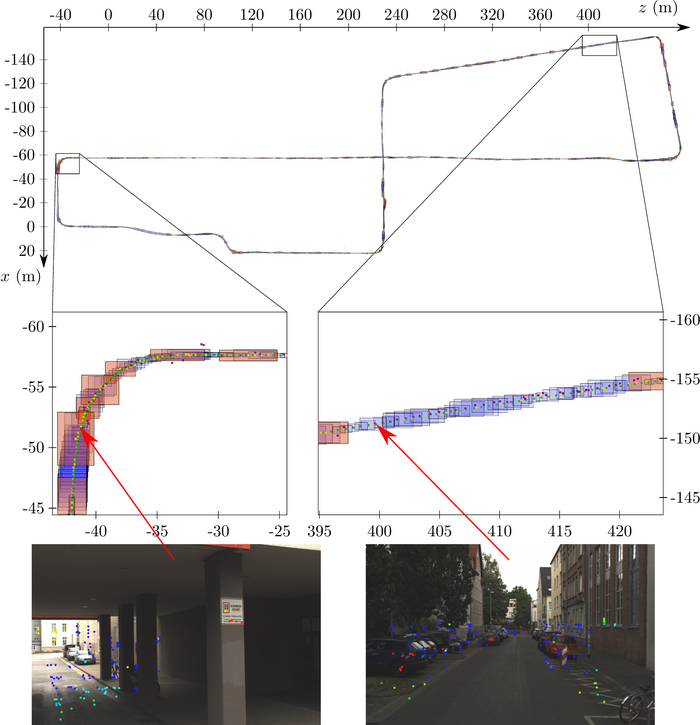
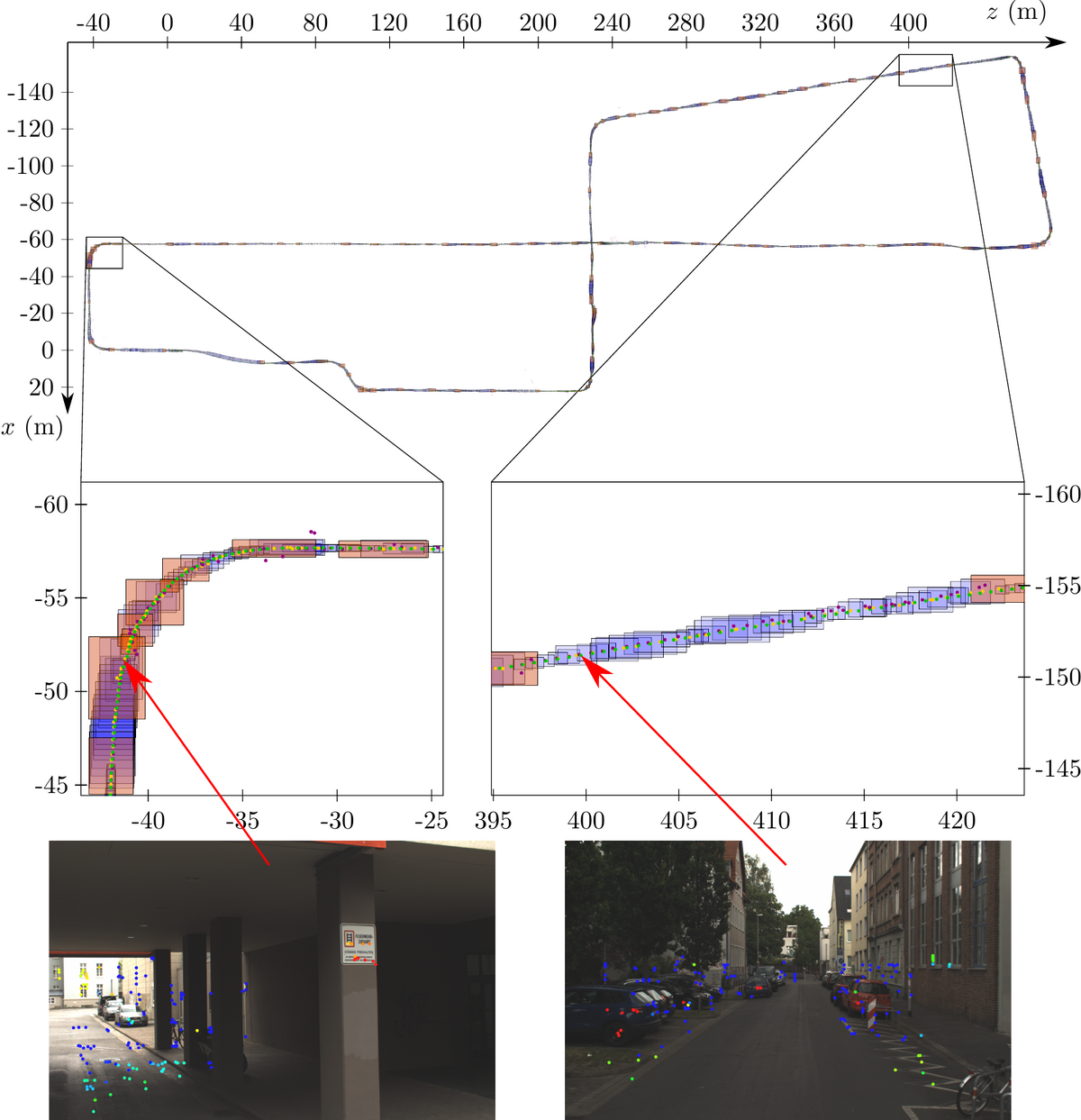
Fig. 2 shows exemplary results of the guaranteed visual-LiDAR odometry approach for our own “mapathon” dataset. Here, the originally three-dimensional results are projected onto the ground plane. Green dots depict the true solution, blue boxes illustrate our interval localization results, orange boxes highlight keyframes and violet dots depict the solution of a stochastic approach. In addition, on the bottom left and right we show feature images that are typical for the corresponding sections of the trajectory. Here, the image features are augmented by depth from the LiDAR and colored coded by depth uncertainty with red signaling accurate features and blue signaling inaccurate features. This depth uncertainty stems from our newly proposed visual-LiDAR sensor fusion approach.
Since we only compute the robot's pose relative to the last keyframe, we use ground truth information at every keyframe to transform the position boxes into a global coordinate system for this visualization. As can be seen, the size and thus the uncertainty of the position boxes as well as the frequency of keyframes vary for different parts of the trajectory. The corresponding images on the bottom of the figure explain this phenomenon. It becomes evident that the image on the right is recorded in an environment, which makes it easy to reidentify image features and to assign accurate depth information to image features on planes parallel to the image plane (e.g. on the cars). Thus, a sufficient number of accurate (colored in red) 3D features can be found which allow to accurately determine the robot’s pose. In contrast, the image on the left is captured in an environment with less rich image features. Moreover, there are fewer features with accurate depth information due to the discontinuity of the environment (e.g. caused by the pillars). Consequently, the constraints introduced by the 3D features of the right image are stronger than those introduced by the 3D features of the left image, thus resulting in a more accurate contraction of the robot's pose at the time of the right image than at the time of the left image.